Transformer Architecture
November 18, 2019 · #google #ai
A few years ago, Google published a research paper called "Attention is All You Need", and let me tell you, it blew my mind! It introduces the Transformer architecture, which feels like a game-changer for natural language processing (NLP). I’ve been tinkering with RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks) for small text-based programs, but this new model shows why the future might not rely on those anymore. Here’s my take on why the Transformer is so cool and why I think it’ll shape the future of machine learning.
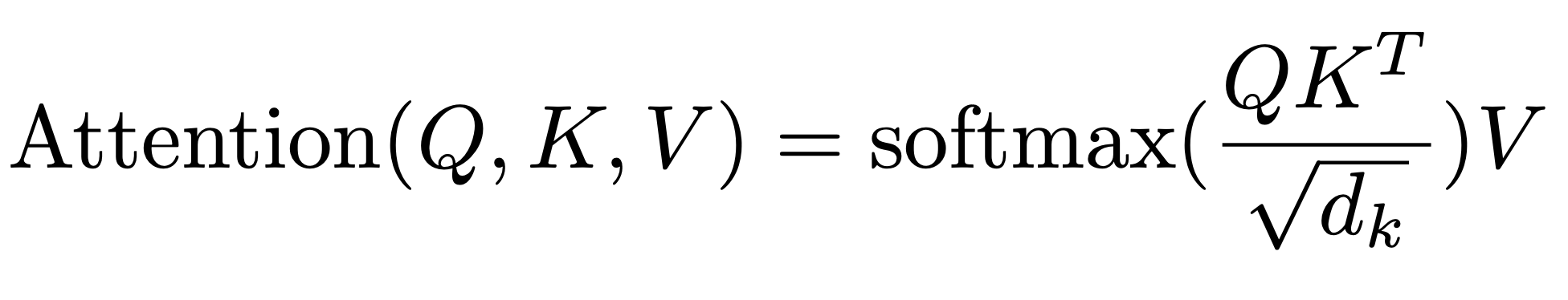
attention as a mechanism that computes weighted sums of values based on the relevance of queries and keys, scaled to ensure stability during training
Table of Contents
- What’s the Transformer?
- Key Features of the Transformer
- Why This Matters?
- My Predictions for the Future
- Conclusion
1. What’s the Transformer?
The Transformer is a deep learning architecture designed to handle sequence-to-sequence tasks like language translation or text summarization. Unlike RNNs, it doesn’t rely on processing words in order (sequentially). Instead, it introduces a mechanism called Self-Attention, which allows it to focus on different parts of the input sentence at the same time!
For example, in a sentence like:
“The cat, which was chasing a mouse, jumped over the fence.”
The Transformer can directly relate "cat" to "jumped" without needing to read every word between them in order. This makes it way faster and better at understanding context.
2. Key Features of the Transformer
2.1 Self-Attention Mechanism
Self-Attention is what makes the Transformer special. It assigns scores to every word in the input sentence, figuring out which words are most important to the current word being processed.
For instance, if you're translating “She sells seashells by the seashore,” the word "seashells" might pay more attention to "sells" than "seashore."
Here's the formula for how it works (it looks scary, but it’s actually straightforward when you break it down):
- Q (Query): Represents the word you're currently processing.
- K (Key): Represents all other words in the input.
- V (Value): Represents the meaning of the words.
This mechanism is why it can figure out which words matter most in a sentence.
2.2 Positional Encoding
Since the Transformer doesn’t process words sequentially like RNNs, it needs a way to know the position of words in a sentence. It uses Positional Encoding, which adds a mathematical pattern (using sine and cosine functions) to each word’s vector.
Think of it as giving each word an address so the Transformer knows where it belongs!
2.3 Parallel Processing
Unlike RNNs, which process words one by one, Transformers process all words simultaneously. This is thanks to Self-Attention and allows for faster training. It’s like having a super-speedy reader instead of someone reading one word at a time.
This makes the Transformer way faster than RNNs and LSTMs.
3. Why This Matters?
Before this, RNNs and LSTMs were the kings of NLP. But they had problems like:
- Being too slow for long sentences.
- Struggling to remember things from earlier in the text.
Transformers solve these issues by:
- Processing all words at once (faster!).
- Using Self-Attention to remember relationships between all words.
This paper also introduces Scaled Dot-Product Attention, which makes the attention calculation efficient even for long sequences.
4. My Predictions for the Future
I think this architecture will lead to:
- Better Language Models: We’ll probably see amazing models for translation, summarization, and even chatbots using Transformers.
- Bigger Networks: Since Transformers process data in parallel, researchers will train much larger models.
- Applications Beyond Text: The attention mechanism might be useful in areas like computer vision (imagine focusing on important parts of an image!).
5. Conclsion
Google’s Transformer architecture feels like a huge leap for AI and NLP. I think tools like this will lead to smarter AI systems that understand text as humans do—or maybe even better. If you’re into AI like me, I’d suggest checking out the paper. Even if some of the math looks complicated, the ideas behind it are simple and super powerful.
In the next few years, don’t be surprised if the Transformer changes everything. I might even build a small program with it someday. Who knows, maybe one day we’ll look back and say, “It all started with Attention.”